Benchmarks
Progress in AI has been driven by high-quality benchmark problems and datasets, which are critically lacking in dynamics and control systems. The Institute is developing and maintaining benchmarks of increasing realism and complexity, aligned with national priority challenges in engineering design, autonomy, manufacturing, and model-based engineering. There are three levels of benchmarks: (1) static data for system identification (completed: CTF); (2) interactive, closed-loop simulation environments that support learning-based control and design optimization (in progress: HydroGym); and (3) network-accessible cyberphysical experiments, enabling agents to be trained, evaluated, and stress-tested against real physical systems (proposed). Our first benchmarks have already had strong community adoption and impact. This progression provides a self-testing framework for AI agents, a pathway toward digital twins, and a unifying platform for education, allowing students to engage with the same benchmark systems that define the research frontier.
Hydrogym is a fluid flow control benchmark environment. This environment uses the OpenAI `gym' API, which has been transformative in the development of advanced reinforcement learning algorithms. This platform allows researchers to interact with considerably more complex physical flow environments. All environments are rigorously validated and benchmarked agains leading RL algorithms.
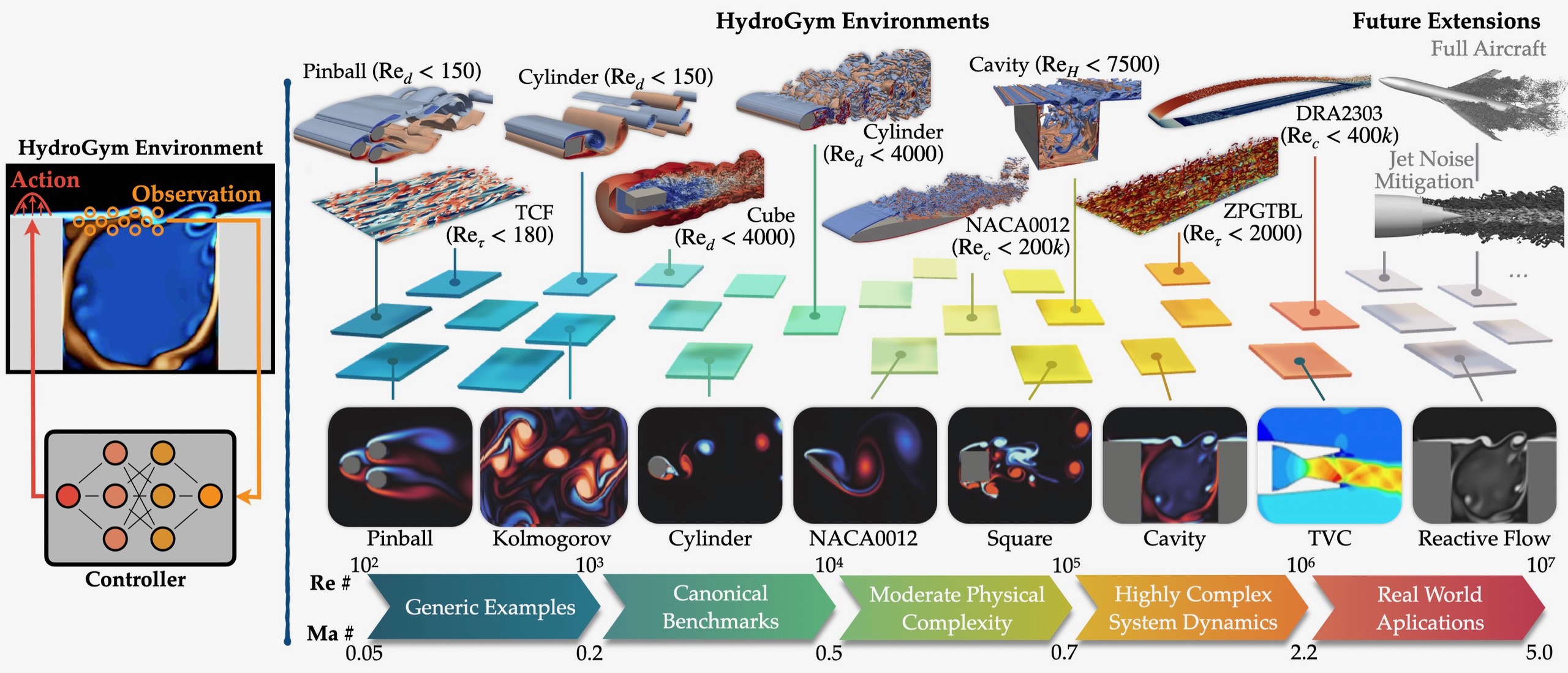
A reinforcement learning platform for fluid dynamics, providing controlled simulation environments and tasks for developing and evaluating flow control strategies: Lagemann et al. (2025). HydroGym: A reinforcement learning platform for fluid dynamics. arXiv:2512.17534. https://arxiv.org/abs/2512.17534
From our fundamental AI advancements in theory and computation, we port our methods to leading grand challenge problems where model complexity, unknown physics, and multiscale and multiphysics phenomena dominate. Critical to reducing methods to practice is a set of application problems where a common task framework (CTF) is used to evaluate methods. This approach has been exceptionally successful in the computer vision and speech recognition communities, where ML/AI has had transformative impact. Our goal is to provide a comprehensive challenge dataset framework for evaluating data-driven methods and their performance across a wide range of tasks for dynamical systems from observational data. We apply this across multiple applications with diverse objectives.

A proposed common task framework for scientific machine learning, introducing shared datasets, metrics, and benchmark tasks: Kutz et al. (2025). Accelerating scientific discovery with the common task framework. arXiv:2511.04001. https://arxiv.org/abs/2511.04001
Application Domains for Benchmarking

FACULTY LEADS


